

La proliferación exponencial de sistemas basados en inteligencia artificial ha transformado radicalmente el panorama tecnológico empresarial contemporáneo. Desde algoritmos de recomendación hasta sistemas autónomos críticos, la IA se ha convertido en el núcleo operativo de innumerables organizaciones. Sin embargo, esta adopción masiva ha generado un ecosistema de vulnerabilidades y vectores de ataque anteriormente inexplorados, demandando un enfoque especializado en seguridad que trasciende los paradigmas tradicionales de ciberseguridad.
El campo de AI Security emerge como disciplina fundamental para proteger no solamente la integridad de los modelos y algoritmos, sino también la confiabilidad de las decisiones automatizadas que impactan directamente en operaciones críticas empresariales. La complejidad inherente de estos sistemas requiere metodologías de análisis de riesgos específicamente diseñadas para abordar amenazas que van desde la manipulación adversarial hasta el envenenamiento de datos de entrenamiento.
Fundamentos técnicos de AI Security.
Taxonomía de amenazas específicas.
Los sistemas de inteligencia artificial enfrentan categorías de amenazas distintivas que requieren comprensión técnica profunda. Los ataques adversariales representan una de las vulnerabilidades más sofisticadas, donde inputs maliciosamente crafteados pueden provocar clasificaciones erróneas en modelos aparentemente robustos. Estas perturbaciones, imperceptibles para observadores humanos, explotan las superficies de decisión no lineales de las redes neuronales.
El envenenamiento de datos constituye otra amenaza crítica, donde adversarios inyectan muestras maliciosas durante la fase de entrenamiento, comprometiendo la integridad del modelo resultante. Esta técnica puede manifestarse tanto en ataques dirigidos (targeting específico de clases) como en degradación general del rendimiento, representando riesgos particulares en entornos de aprendizaje continuo.
Arquitecturas de defensa multicapa.
La implementación de defensas robustas requiere arquitecturas multicapa que abarquen desde la validación de inputs hasta la monitorización post-despliegue. Las técnicas de adversarial training han demostrado eficacia parcial, aunque introducen trade-offs en términos de rendimiento computacional y capacidad de generalización.
La detección de anomalías basada en aprendizaje no supervisado ofrece capacidades prometedoras para identificar desviaciones en patrones de input que podrían indicar intentos de manipulación. Estas implementaciones frecuentemente utilizan autoencoders variacionales o redes generativas adversariales para establecer representaciones de distribuciones normales de datos.
Frameworks de seguridad establecidos.
NIST AI risk management framework (AI RMF 1.0)
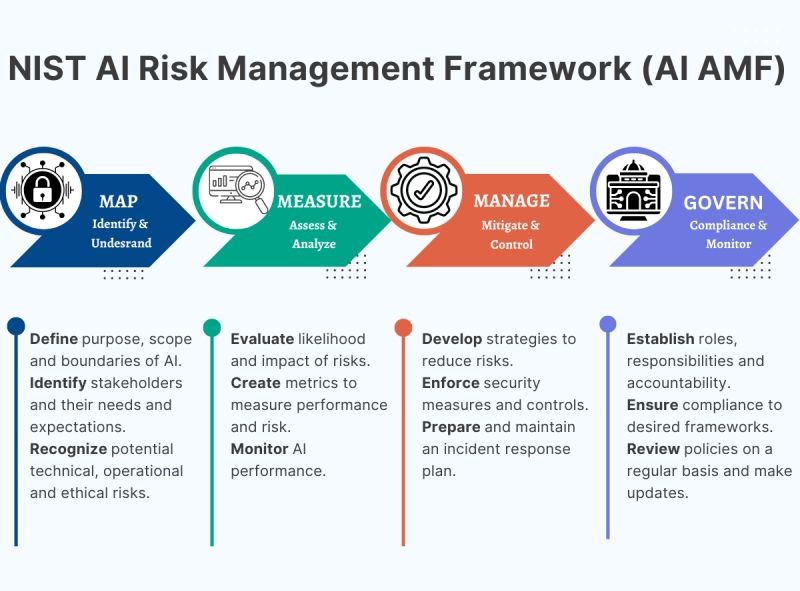
El marco de gestión de riesgos de IA del Instituto Nacional de Estándares y Tecnología establece directrices comprensivas para la identificación, evaluación y mitigación de riesgos asociados con sistemas de IA. Su estructura se fundamenta en cuatro funciones principales: Govern, Map, Measure y Manage.
La función «Govern» enfatiza el establecimiento de políticas organizacionales y estructuras de gobernanza que faciliten la gestión responsable de riesgos de IA. Esto incluye la definición de roles y responsabilidades específicos para equipos multidisciplinarios, incorporando perspectivas técnicas, éticas y regulatorias.
La función «Map» se centra en la contextualización de sistemas de IA dentro del ecosistema organizacional, identificando interdependencias, stakeholders afectados y potenciales impactos socioeconómicos. Esta fase requiere análisis exhaustivos de casos de uso, poblaciones objetivo y métricas de rendimiento relevantes.
Las funciones «Measure» y «Manage» abordan la implementación de métricas cuantitativas para la evaluación continua de riesgos y la ejecución de estrategias de mitigación adaptativas. El framework enfatiza la importancia de la monitorización continua y la actualización iterativa de evaluaciones de riesgo conforme evoluciona el sistema.
MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems)
MITRE ATLAS proporciona un framework estructurado para comprender y categorizar amenazas adversariales específicamente dirigidas a sistemas de inteligencia artificial. Su metodología se basa en la taxonomía TTPs (Tactics, Techniques, and Procedures) adaptada para el contexto de IA.
El framework identifica tácticas fundamentales incluyendo Reconnaissance, Resource Development, Initial Access, ML Model Access, Exfiltration e Impact. Cada táctica encompasa técnicas específicas documentadas con casos de estudio reales y contramedidas recomendadas.
La táctica de «ML Model Access» resulta particularmente relevante, abarcando técnicas como model inversion attacks, membership inference y model extraction. Estas técnicas permiten a adversarios obtener información sensible sobre datos de entrenamiento o replicar funcionalidades de modelos propietarios.

Consideraciones de implementación práctica.
Evaluación de robustez y testing adversarial.
La implementación efectiva de AI Security demanda metodologías de testing que trasciendan evaluaciones tradicionales de rendimiento. El testing adversarial sistemático debe incorporar generación automatizada de casos de prueba adversariales utilizando técnicas como Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), y C&W attacks.
Estas evaluaciones deben considerar múltiples métricas, incluyendo robustez certificable, donde se pueden establecer garantías matemáticas sobre la resistencia del modelo a perturbaciones dentro de normas específicas. Técnicas como interval bound propagation y abstract interpretation ofrecen enfoques prometedores para la verificación formal de propiedades de seguridad.
Monitorización y detección de anomalías en producción.
Los sistemas de IA en producción requieren capacidades de monitorización continua que puedan detectar degradación de rendimiento, drift de datos, e intentos de manipulación adversarial. La implementación de sistemas de alertas basados en métricas de incertidumbre, drift detection, y análisis de distribuciones de activaciones puede proporcionar indicadores tempranos de compromisos de seguridad.
Las técnicas de explicabilidad e interpretabilidad, incluyendo SHAP (SHapley Additive exPlanations) y LIME (Local Interpretable Model-agnostic Explanations), pueden facilitar la identificación de patrones anómalos en el comportamiento del modelo que podrían indicar manipulación adversarial.
Tendencias emergentes y consideraciones futuras.
Federated Learning Security
El aprendizaje federado presenta desafíos únicos de seguridad, donde múltiples participantes colaboran en el entrenamiento de modelos sin compartir datos directamente. Los ataques de envenenamiento de modelo y los intentos de inferencia sobre datos privados de participantes representan amenazas críticas que requieren técnicas especializadas como differential privacy y secure aggregation.
AI Supply Chain Security.
La complejidad de las cadenas de suministro en IA, incluyendo datasets pre-entrenados, modelos base, y bibliotecas de third-party, introduce vectores de ataque adicionales. La verificación de integridad de componentes, provenance tracking y evaluación de riesgos de dependencias se convierten en aspectos fundamentales de una estrategia comprensiva de AI Security.
Quantum-Safe AI.
El desarrollo de computación cuántica presenta implicaciones a largo plazo para la seguridad de sistemas de IA, particularmente aquellos que dependen de criptografía tradicional para la protección de modelos y datos. La investigación en algoritmos postcuánticos y su integración con sistemas de IA representa un área de desarrollo crítica para la resiliencia a largo plazo.

Conclusiones y recomendaciones estratégicas.
La seguridad de sistemas de inteligencia artificial requiere un enfoque holístico que integre consideraciones técnicas, organizacionales y regulatorias. La adopción de frameworks establecidos como NIST AI RMF y MITRE ATLAS proporciona fundamentos sólidos, pero debe complementarse con implementaciones técnicas específicas adaptadas a contextos organizacionales particulares.
Las organizaciones deben priorizar el desarrollo de capacidades internas especializadas en AI Security, incluyendo personal técnico con expertise en adversarial machine learning, evaluación de robustez e implementación de defensas multicapa. La colaboración interdisciplinaria entre equipos de seguridad, desarrollo de IA y cumplimiento regulatorio resulta fundamental para el éxito de estas iniciativas.
La evolución continua del panorama de amenazas demanda enfoques adaptativos que puedan evolucionar junto con las capacidades adversariales emergentes. La inversión en investigación y desarrollo de técnicas defensivas, combinada con participación activa en comunidades de seguridad especializadas, representa elementos críticos para mantener una postura de seguridad efectiva en el contexto de sistemas de IA empresariales.
Fuente: https://atlas.mitre.org/
