

El problema de la convergencia no modelada.
Hay una premisa que los programas de implementación de IA en industria tienden a asumir sin cuestionarla: que el sistema de IA es un elemento de soporte, externo al proceso, que puede ser evaluado de forma independiente a la infraestructura sobre la que opera. Esa premisa es incorrecta — y el costo de sostenerla se pagará, tarde o temprano, con un incidente.
Cuando un modelo de mantenimiento predictivo decide que las lecturas de vibración de una turbina están dentro de parámetros normales, no está ejecutando una función de IT. Está condicionando una decisión operacional con consecuencias físicas directas. Lo mismo aplica a los modelos de optimización de producción, a los sistemas de detección de anomalías en procesos, y a los asistentes de decisión para operadores. La IA en entornos OT no opera en un silo: opera sobre datos de proceso, informa actuadores, y su output tiene la misma capacidad de afectar continuidad operacional que cualquier otro componente del sistema de control.
El problema de fondo tiene dos caras.
Por el lado de los equipos OT: la comunidad de seguridad industrial conoce en profundidad las 12 tácticas y técnicas de MITRE ATT&CK for ICS. Sabe modelar T0831 (Manipulation of Control), T0878 (Alarm Suppression), T0832 (Manipulation of View). Pero no tiene un modelo para el escenario donde el vector de ataque no es el PLC ni el HMI directamente — sino el modelo de IA que procesa los datos de esos activos y genera las recomendaciones sobre las que actúan los operadores.
Por el lado de AI Security: MITRE ATLAS, OWASP ML Security Top 10 y los demás frameworks diseñados para sistemas de IA cubren razonablemente bien ataques como data poisoning, model evasion o model inversion. Lo que no contemplan es que el output dañino de un modelo comprometido puede ser, en un entorno industrial, una señal de control en SCADA o un ajuste de parámetros en un historian. La diferencia no es técnica — es de consecuencias.
El resultado es una superficie de ataque que cae en el espacio entre los dos frameworks. Ninguno la cubre por sí solo, y la mayoría de las organizaciones no tienen a nadie mirando específicamente ese espacio.
- Taxonomía de vectores: donde ATLAS y ATT&CK for ICS se intersectan
Para hacer operativa la brecha que se describió, conviene examinar las tácticas de MITRE ATLAS y rastrear qué impactos producirían en el contexto de ATT&CK for ICS. El ejercicio revela algo relevante: los ataques adversariales contra sistemas de IA no son una amenaza abstracta o futura — son variantes de objetivos que los equipos OT ya conocen, ejecutadas por vectores que aún no han incorporado a sus modelos de amenaza.
2.1 Reconocimiento orientado al proceso industrial
MITRE ATLAS identifica como primera táctica el reconocimiento del sistema objetivo. Las técnicas AML.T0000 (Search for Victim’s Publicly Available Research Materials) y AML.T0002 (Acquire Public ML Artifacts) documentan cómo los adversarios mapean la arquitectura de los modelos en uso antes de atacarlos. En entornos IT esto se traduce en información sobre librerías y versiones. En entornos OT, la implicación es distinta: el adversario que entiende qué modelo de optimización corre una planta — y con qué datos fue entrenado — puede inferir la topología de su red de sensores, sus parámetros operacionales, y los rangos de normalidad que el modelo aprendió. La exfiltración de metadatos del modelo puede revelar tanto como un diagrama de proceso.
2.2 Training Data Poisoning como vector de Alarm Suppression
AML.T0020 (Poison Training Data) es, probablemente, el vector con mayor potencial de daño sostenido en entornos industriales. El mecanismo es el siguiente: un adversario que logra contaminar el pipeline de datos de entrenamiento de un modelo predictivo con lecturas manipuladas puede conseguir que ese modelo internalice como normales condiciones que deberían disparar alertas. No suprime la alarma directamente — enseña al modelo que esa condición no requiere alarma.
El efecto final se alinea con T0878 (Alarm Suppression) de ATT&CK for ICS, pero el vector es completamente diferente. No hay acceso directo al sistema de control, no hay modificación de lógica de PLC, no hay tráfico anómalo sobre protocolos industriales. Lo que hay es un dataset de entrenamiento con muestras estratégicamente alteradas, posiblemente semanas o meses antes del incidente que habilita.
Este escenario no está modelado en ATT&CK for ICS porque no involucra compromiso de activos OT en la fase de ataque activo. Tampoco está completamente capturado en ATLAS porque los frameworks de AI security no tienen, por defecto, una noción de «consecuencia física» del modelo comprometido. Cae exactamente en la brecha entre ambos.
2.3 Model Evasion como Manipulation of View
AML.T0043 (Craft Adversarial Data) documenta la técnica de construir inputs que explotan las debilidades del modelo para obtener clasificaciones incorrectas. En un contexto de visión artificial o análisis de series temporales sobre datos de proceso, esto se traduce en que condiciones físicamente anómalas son clasificadas como normales por el modelo. El operador toma decisiones sobre una representación del proceso que no corresponde a la realidad.
Funcionalmente, es T0832 (Manipulation of View). La diferencia con respecto al ataque ICS tradicional está en la detectabilidad. Una manipulación del HMI deja trazas forenses: modificaciones en archivos, tráfico fuera de baseline, cambios en registros del sistema. Un adversarial input bien construido puede activar la condición de forma intermitente, sin artifacts obvios en los logs convencionales. El vector es más silencioso.
2.4 La tabla de convergencia
El siguiente cuadro sintetiza el mapeo entre tácticas de MITRE ATLAS y técnicas de Impact de ATT&CK for ICS. No es exhaustivo — es ilustrativo del patrón: cada táctica adversarial contra el sistema de IA tiene un análogo funcional en los impactos ICS que los equipos operacionales ya conocen. La novedad es el camino, no el destino.
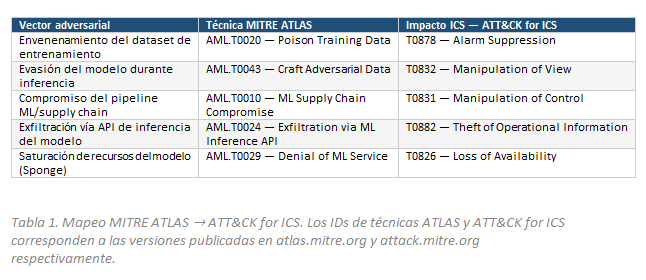
- La brecha estructural en los frameworks actuales
Plantear el problema no es suficiente sin reconocer por qué persiste. No es ignorancia — los equipos de seguridad OT y los equipos de MLOps son, por separado, técnicamente capaces. El problema es estructural: los frameworks que usan están diseñados para mundos distintos, y ninguno de los dos tiene incentivo para extenderse hacia el otro.
NIST AI RMF, en su forma actual, lleva a los equipos de implementación a evaluar riesgos de bias, fairness, robustez estadística y privacidad. ISO/IEC 42001 agrega un sistema de gestión formal con audit trails y procesos de gobernanza de modelos. Ambos frameworks son sólidos para lo que fueron diseñados. Pero ninguno contempla, como caso de uso estándar, que el deployer del sistema de IA es un entorno donde la accuracy degradada del modelo puede resultar en pérdida de control de un proceso físico. Esa conexión no está en el scope.
IEC 62443, por su parte, define zonas de seguridad, conduits y niveles de protección para activos OT con una solidez que pocos frameworks industriales igualan. El problema es que su modelo de activos no incorpora el ciclo de vida de un modelo de ML como un activo con superficies de ataque propias. El training pipeline, el inference endpoint, el data pipeline, el model registry — ninguno tiene representación natural en la taxonomía de IEC 62443.
De esta tensión emergen tres consecuencias concretas.
Los impact assessments de IA están incompletos. Se modelan riesgos de calidad del output y de privacidad, pero no las consecuencias físicas de un modelo comprometido o en degradación. La pregunta «¿qué pasa si el modelo falla?» se responde en términos estadísticos, no operacionales.
Los controles no convergen. Los equipos IT/OT implementan controles sobre los sistemas de control. Los equipos de MLOps implementan controles sobre el ciclo de vida del modelo. El espacio entre ambos — el canal por el cual el output del modelo se convierte en señal de proceso o en recomendación operacional — está, en la mayoría de las organizaciones, sin dueño.
La detección está segmentada. Un SOC industrial monitoriza tráfico Modbus, OPC-UA y modificaciones en PLCs. Un equipo de MLOps monitoriza accuracy, latencia y drift del modelo. Detectar un ataque que degrada el modelo para suprimir alarmas requiere correlacionar ambas fuentes — y esa correlación no existe por defecto en ninguna de las dos disciplinas.
- Controles específicos para AI en entornos OT
La respuesta a esta brecha no pasa por reemplazar los frameworks existentes. Los equipos que intentan construir un framework nuevo desde cero suelen terminar con algo menos maduro que NIST AI RMF o IEC 62443 por separado. Lo que hace falta es extensión: controles específicos para la intersección, organizados según la fase del ciclo de vida del sistema de IA en la que son aplicables.
4.1 Fase de diseño: threat modeling que cruce los dos mundos
El threat modeling de un sistema de IA destinado a operar en entornos OT no puede hacerse sobre una sola superficie. Tiene que correr simultáneamente sobre la superficie del sistema de IA — usando MITRE ATLAS y OWASP ML Security Top 10 — y sobre la superficie del proceso industrial que el modelo informa o controla, usando MITRE ATT&CK for ICS.
El output del ejercicio no es una lista de vulnerabilidades del modelo. Es un mapa de cadenas de ataque completas:
Vector adversarial → Mecanismo de degradación del modelo → Impacto en proceso físico
La pregunta correcta no es «¿cómo puede ser comprometido este modelo?» La pregunta correcta es «dado que este modelo puede degradarse por estos vectores, ¿qué consecuencia operacional específica tiene esa degradación en este proceso?». Es una distinción que cambia completamente qué controles son prioritarios.
4.2 Fase de entrenamiento: el data pipeline como perímetro de seguridad
Los pipelines de datos que alimentan modelos entrenados con señales de proceso OT deben recibir los mismos controles de integridad que se aplican a los sistemas de control. En la práctica esto implica tres cosas que raramente ocurren juntas:
Data lineage y provenance obligatorios. Sin trazabilidad del origen de cada muestra de entrenamiento, la detección post-facto de data poisoning es casi imposible. Si no se puede responder «¿de dónde viene este dato y quién tuvo acceso a modificarlo antes de ingresar al dataset?», el pipeline tiene un punto ciego que un adversario puede explotar con relativa comodidad.
Validación estadística pre-entrenamiento. Distribuciones anómalas, outliers sistemáticos y cambios sostenidos en la distribución de features críticas deben generar alertas antes de que el dataset sea consumido. Esto no reemplaza la revisión humana — la complementa y la hace viable a escala.
Separación de ambientes entre el pipeline de datos de entrenamiento y los sistemas de proceso activos. Un adversario que compromete el sistema de proceso no debería tener, como consecuencia natural, la capacidad de contaminar el próximo ciclo de entrenamiento del modelo. Esa separación tiene que ser explícita, no asumida.
4.3 Fase de deployment: least privilege aplicado al contexto OT
El principio de least privilege tiene una traducción específica en este contexto: los modelos de IA desplegados en entornos OT operan sobre los datos necesarios para su función y tienen capacidad de influir sobre los outputs explícitamente definidos en su especificación funcional — nada más. Las conexiones adicionales, los accesos amplios por conveniencia operacional, los permisos heredados del sistema de integración: todos son superficie de ataque.
El corolario más importante es la obligatoriedad del human-in-the-loop para acciones de alto impacto operacional. Un modelo puede recomendar detener un proceso o ajustar un parámetro crítico. La decisión de ejecutar esa recomendación no debería ser automática, independientemente del nivel de confidence que reporte el modelo. Si el modelo está comprometido, su nivel de confidence puede ser alto y su recomendación, incorrecta. Human-in-the-loop no es un freno a la automatización — es el control que evita que un modelo degradado ejecute acciones irreversibles sin supervisión.
4.4 Fase operacional: detección cruzada como disciplina
La detección de ataques que operan a través del modelo de IA requiere correlacionar dos fuentes que, en la arquitectura operacional típica, viven en mundos separados.
Por un lado, las métricas del modelo: accuracy en producción, distribution shift en inputs, latencia de inferencia, volúmenes y patrones de consulta al endpoint. Un modelo que empieza a recibir queries sistemáticamente diseñadas para mapear su behavior está siendo atacado — y eso es detectable si alguien está mirando los logs correctos.
Por otro lado, las métricas del proceso: qué comportamiento tuvo el proceso en los períodos donde el modelo generó recomendaciones específicas. Si el modelo clasificó una condición como normal y el proceso posterior exhibió comportamiento que los operadores habrían identificado como anómalo, esa divergencia es una señal de investigación. No prueba un ataque, pero justifica uno.
Esta correlación cruzada es la base de la detección de adversarial examples en inferencia y de los modelos que han sido envenenados para normalizar condiciones específicas. El modelo no genera errores visibles en sus propias métricas internas — su influencia sobre el proceso es la señal. Y esa señal solo es visible si alguien integra las dos fuentes.
- Implicaciones para los programas de implementación
Los programas de implementación de IA en procesos industriales — sean de mantenimiento predictivo, optimización de producción o asistencia a operadores — están creciendo en sofisticación técnica con más rapidez que en madurez de seguridad. El gap no es de conocimiento: es de integración. Los tres elementos que siguen están, con frecuencia, ausentes.
Un perfil que conozca los dos dominios
Los programas de AI en OT necesitan alguien que pueda conversar con el equipo de MLOps sobre gradientes y distribuciones, y con el equipo de seguridad industrial sobre zonas Purdue y protocolos industriales. No es un perfil común — pero es el perfil que puede ver la brecha completa. La segmentación actual entre los dos equipos produce programas donde la superficie de riesgo de la intersección no tiene dueño claro.
Un threat model que explicite la cadena AI → proceso
Evaluar la robustez del modelo de forma aislada no es suficiente. El threat model tiene que responder algo más específico: dado que este modelo puede ser comprometido o degradado por estos vectores, ¿cuál es el impacto concreto sobre el proceso que informa? La respuesta cambia completamente el mapa de prioridades — hay vectores de ataque de baja sofisticación técnica que, en el contexto correcto, habilitan impactos de alta consecuencia.
Criterios de degradación aceptable y mecanismos de fallback definidos
Todo sistema de IA en entornos OT necesita dos definiciones que raramente están documentadas: cuánta degradación de performance es aceptable antes de desactivar el modelo, y qué proceso operacional toma el control cuando el modelo es retirado. Esas definiciones no son solo criterios de calidad — son controles de ciberseguridad. Un adversario que degrada el modelo gradualmente puede mantenerse bajo el umbral de detección si ese umbral no está definido con precisión.
Conclusión
La integración de IA en entornos OT/ICS no introduce tipos de impacto desconocidos. Loss of Control, Loss of View y Alarm Suppression son amenazas que la comunidad de seguridad industrial conoce desde hace años. Lo que introduce la IA es un vector nuevo para esos impactos — un vector que los frameworks existentes no cubren de forma integrada, y que la mayoría de los programas de implementación actuales no están modelando.
Cerrar esa brecha no requiere un framework completamente nuevo. Requiere tres cosas más acotadas: mapear las tácticas de MITRE ATLAS sobre los impactos de ATT&CK for ICS como parte estándar del threat modeling de cualquier sistema de IA en entornos industriales; extender el modelo de activos de IEC 62443 para incorporar el ciclo de vida del modelo de ML; y diseñar programas de implementación que incluyan el threat modeling cruzado como entregable, no como ejercicio opcional.
Los equipos que avanzan sobre esta integración antes de que sea obligatoria por regulación o por incidente construyen algo difícil de replicar rápidamente: la capacidad de detectar y responder a una superficie de ataque que la mayor parte de la industria todavía no ha terminado de nombrar.
Fuentes
MITRE ATT&CK for ICS (attack.mitre.org)
Koay et al. (2022), Journal of Intelligent Information Systems, Springer
MITRE ATLAS v4.9.1 (atlas.mitre.org)
Ahmad Rana (enero 2026), SSRN
Kravchik, Biggio & Shabtai (2021), ACM SAC
NIST AI RMF 1.0 (2023)
ISO/IEC 42001:2023
IEC 62443
